本地部署开源大模型
最近在GitHub上发现一个开源项目llama.cpp,llama.cpp的主要目标是在本地和云端,以最小的设置和最先进的性能实现 LLM 推理。这让个人电脑本地部署开源大模型成为可能,如果你有兴趣可以前往llama.cpp的GitHub仓库查看更多详情。虽然llama.cpp使用还是比较简单,但他的命令行界面还是需要一点编程基础,这里我们使用一个对llama.cpp进行二次分装的半开源工具:LM Studio来进行演示,当然你也可以使用其他像Ollama之类的工具(这里不过多赘述)。
部署流程
1)安装LM Studio
直接前往LM Studio的官网下载安装即可。
2)设置
用GitHub或者其他方式登录之后
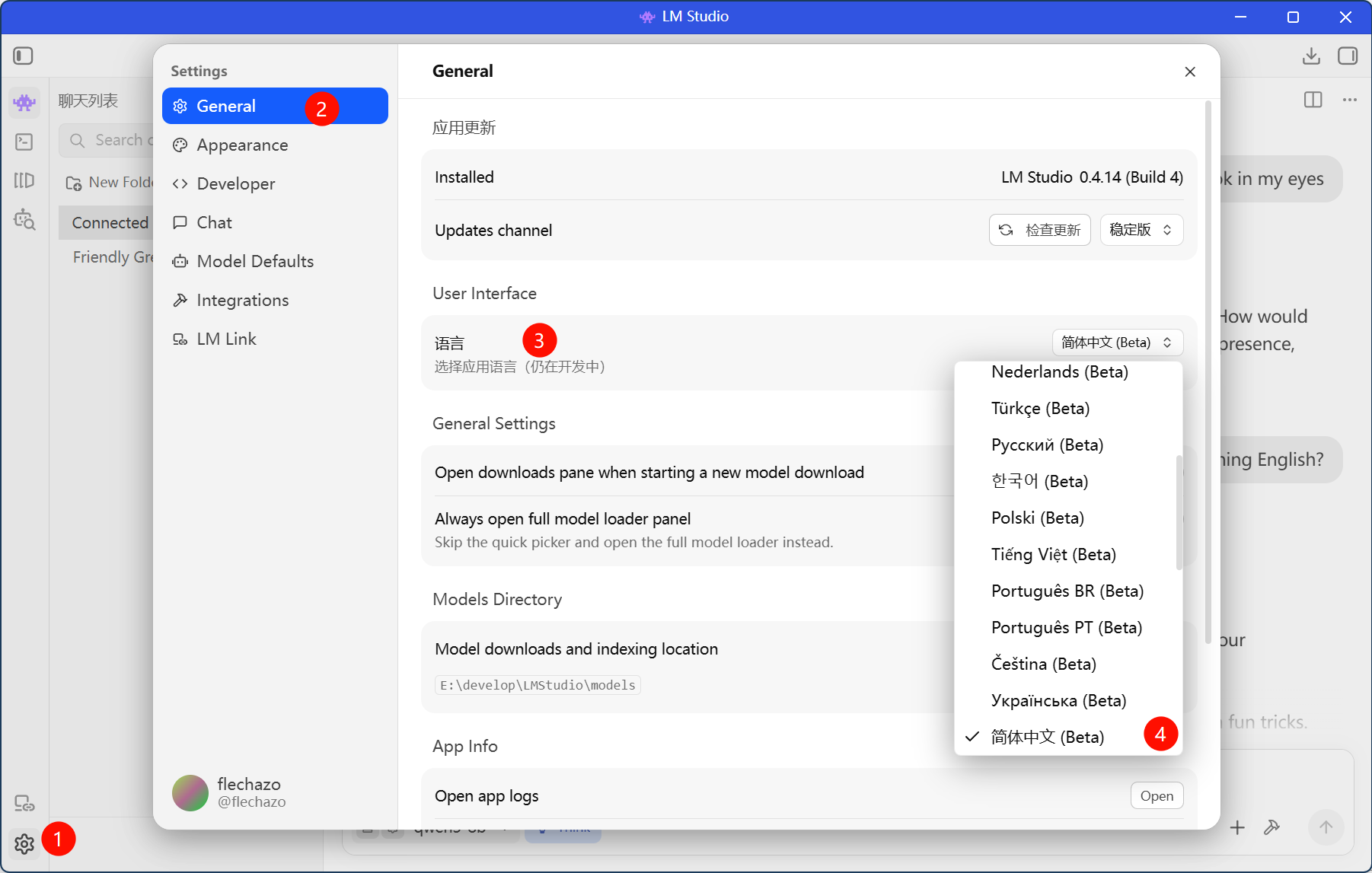
点进左下角settings->General->language,选择中文,但是中文包可能不全面,还会是中英文混合显示,考虑到界面也比较简单,还是推荐用英文。
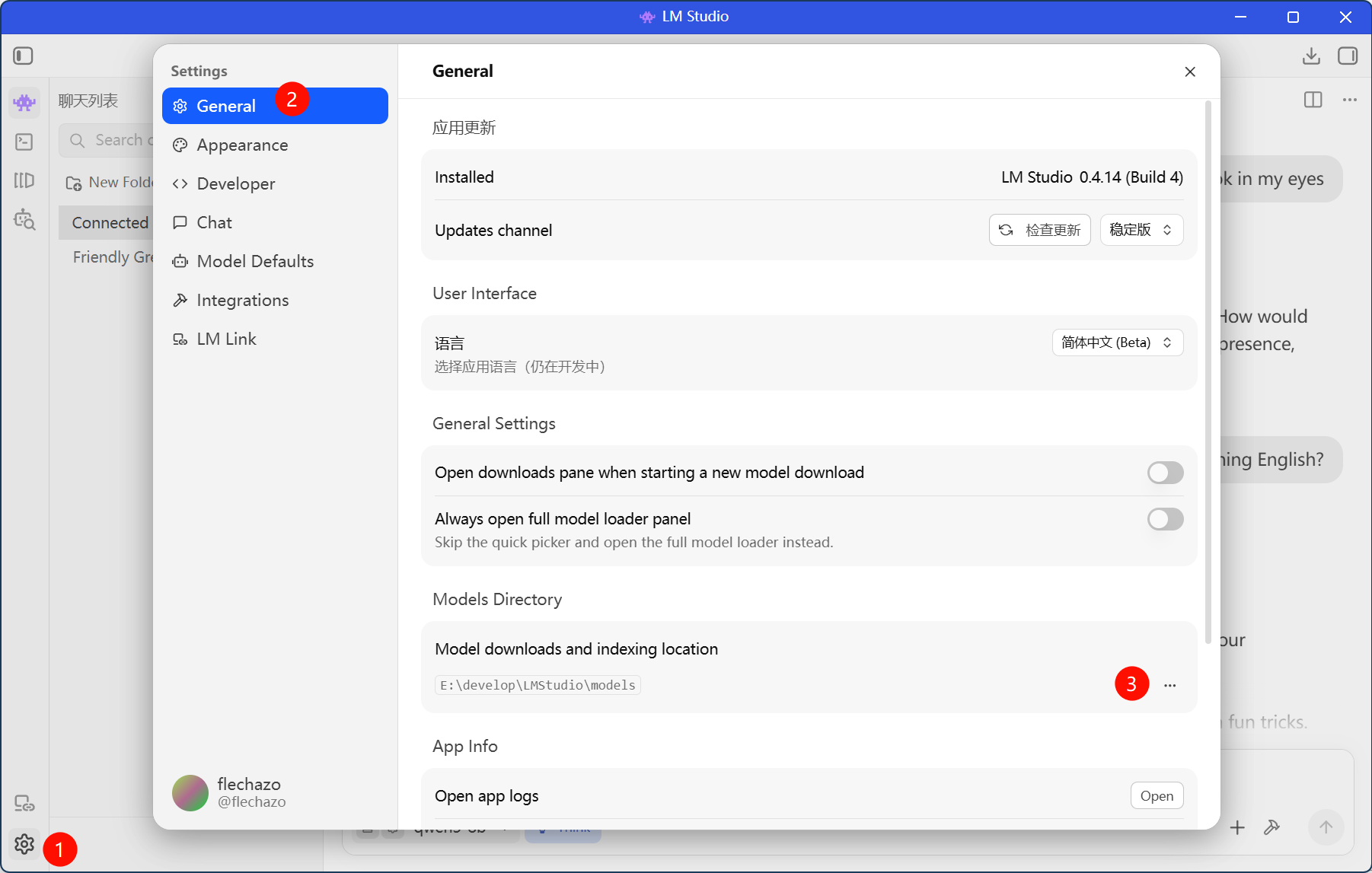
点进左下角settings->General->Models Directory,选择你下载的模型目录,默认会在C盘,这里可以改成其他目录。
3)下载模型
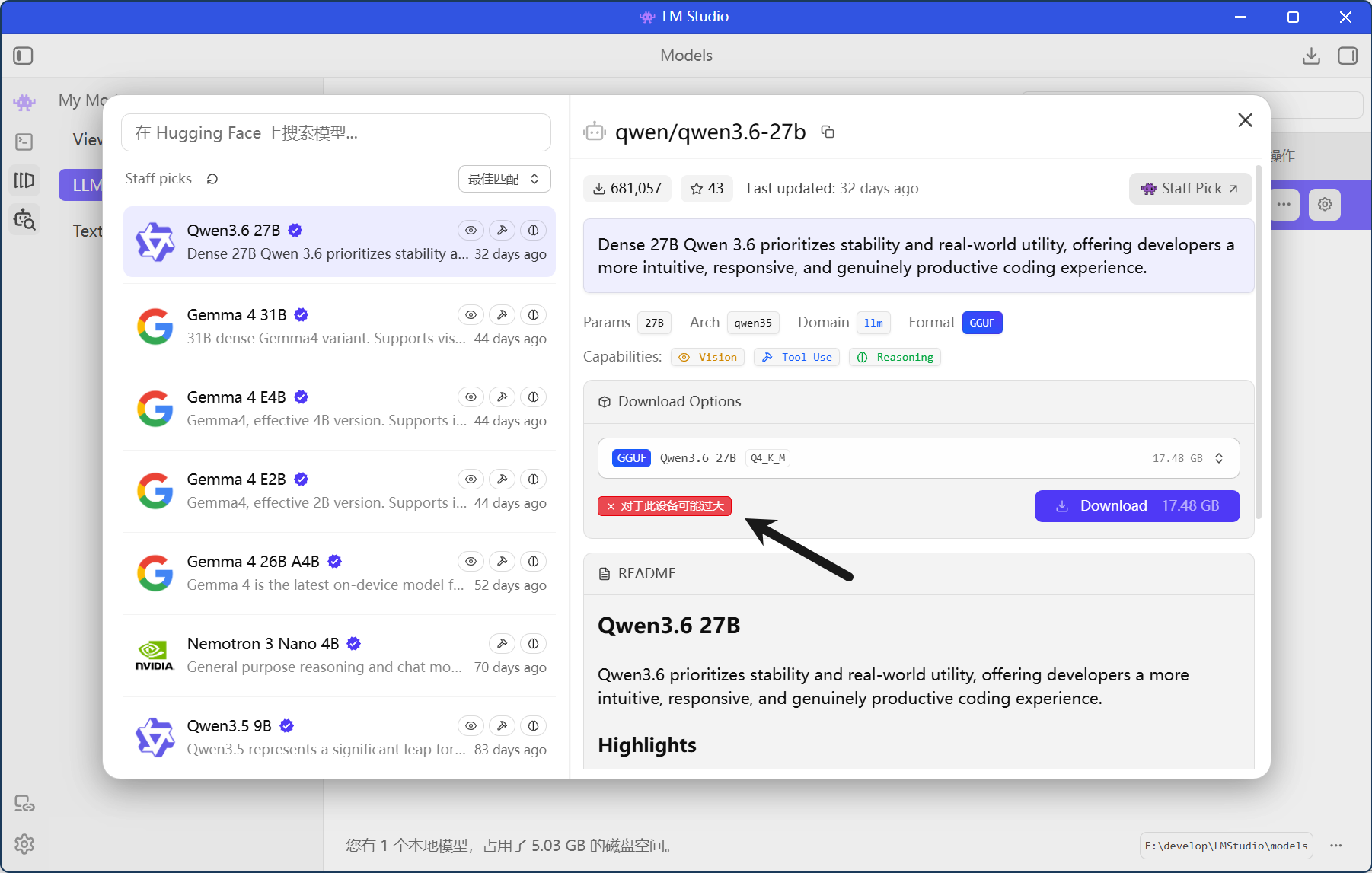
完成设置之后就可以下载模型了,点击右侧的Model Search(或者快捷键ctrl+shift+M),搜索你想要的模型,点击下载即可。
在下载模型界面软件还贴心的提示你的电脑配置是否能够运行这个模型。你可以根据需要选择模型,也可以问deepseek你的电脑配置最适合哪个模型,这里我用Qwen3-8b做演示,搜索模型名称后点击下载。
4)运行模型
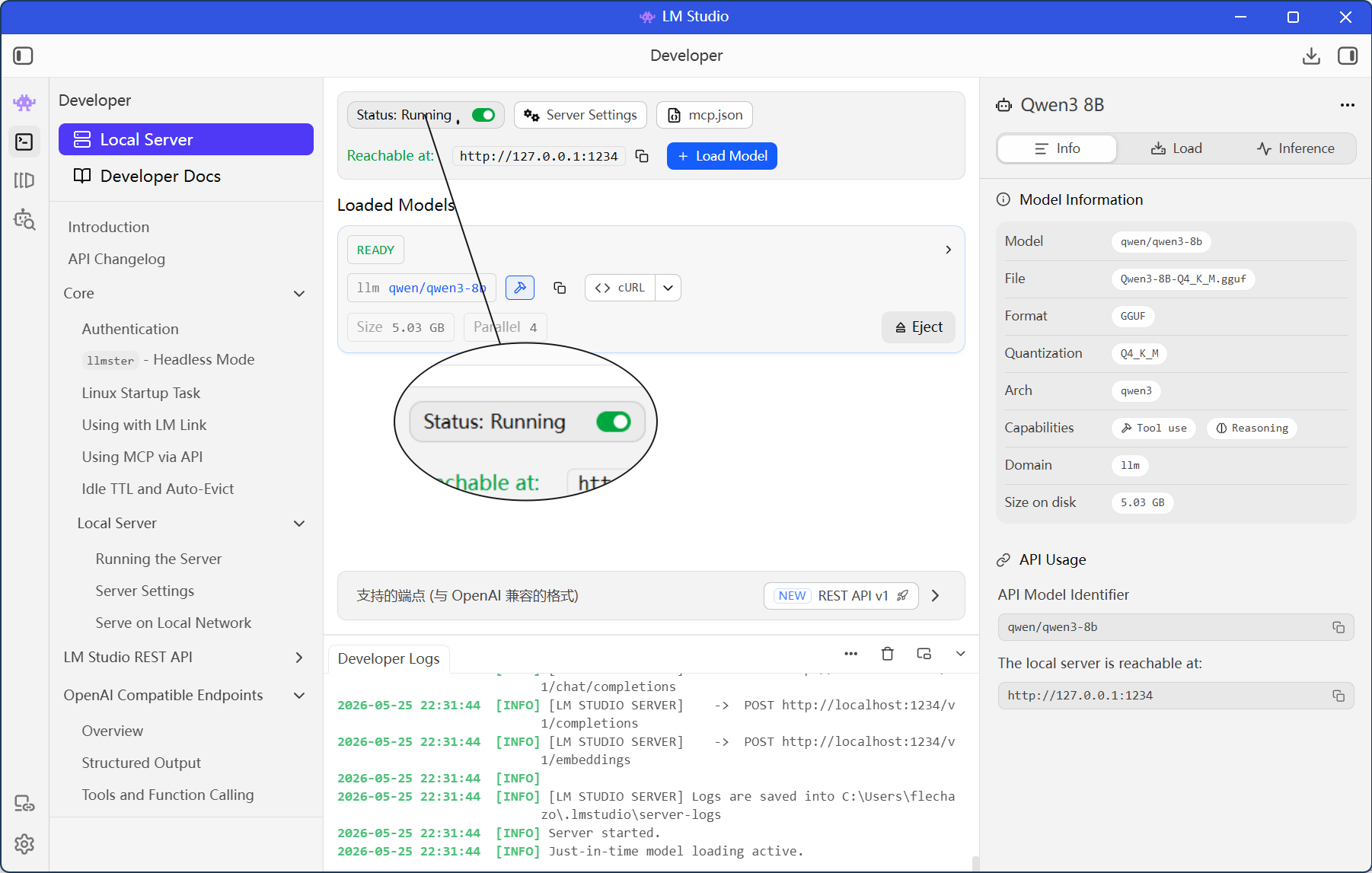
下载好之后选择Developer->Local Server,就可以看到你下载的模型了。
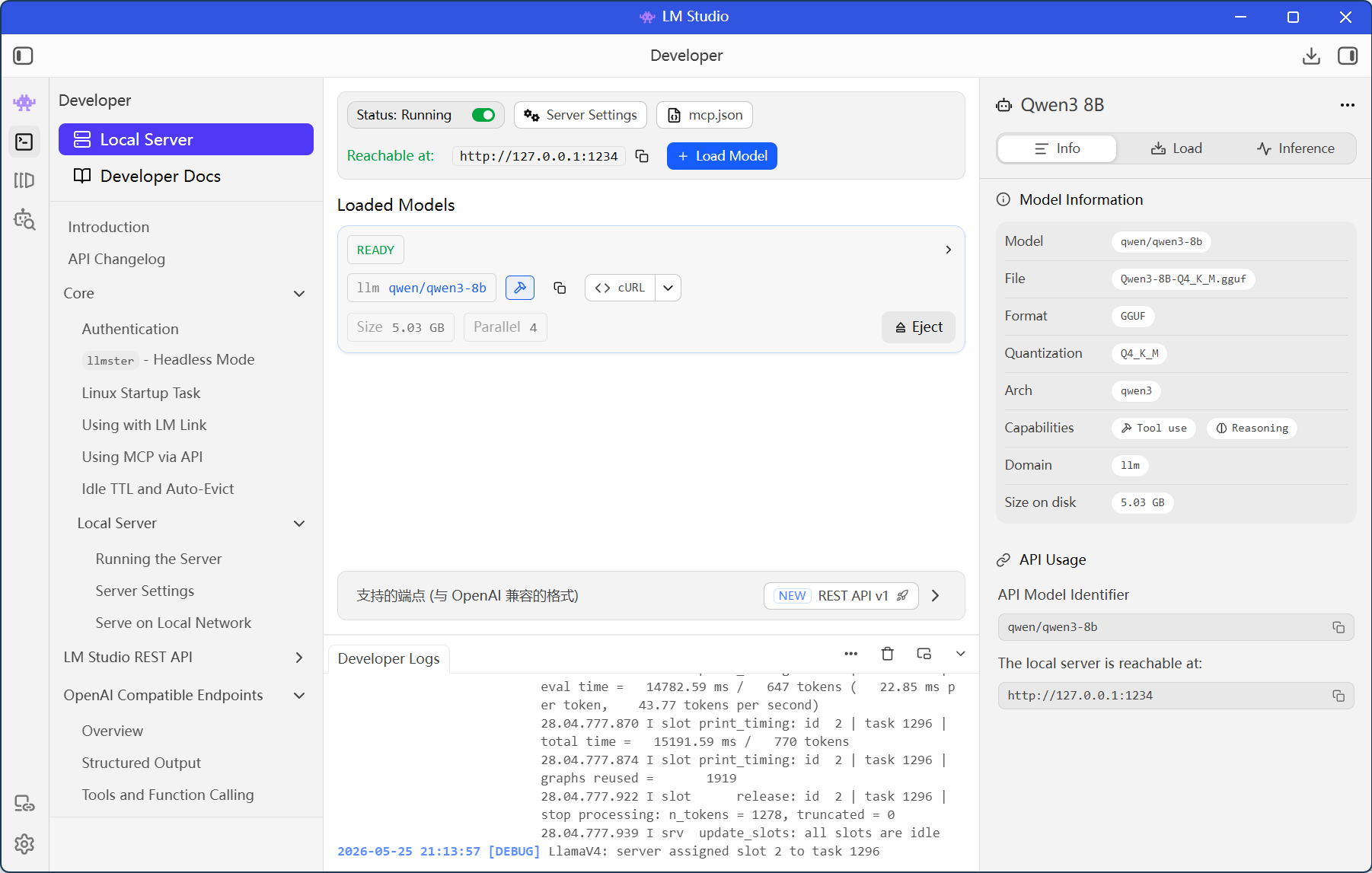
点击右上角的status开关,当显示running时,说明模型已经启动了。
测试
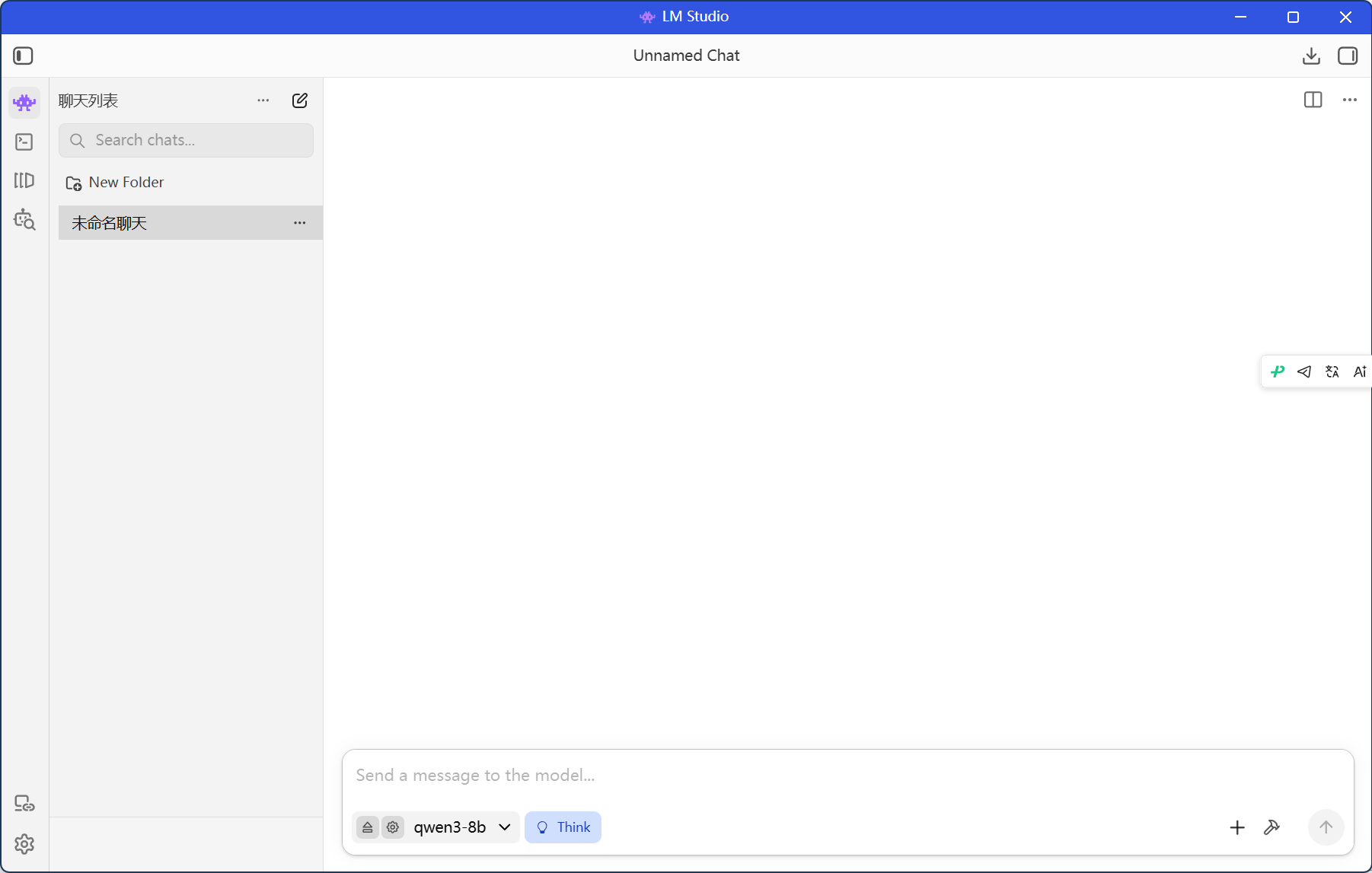
点击右侧的Chat按钮,选择刚才部署的本地模型就可以开始与模型交互了。
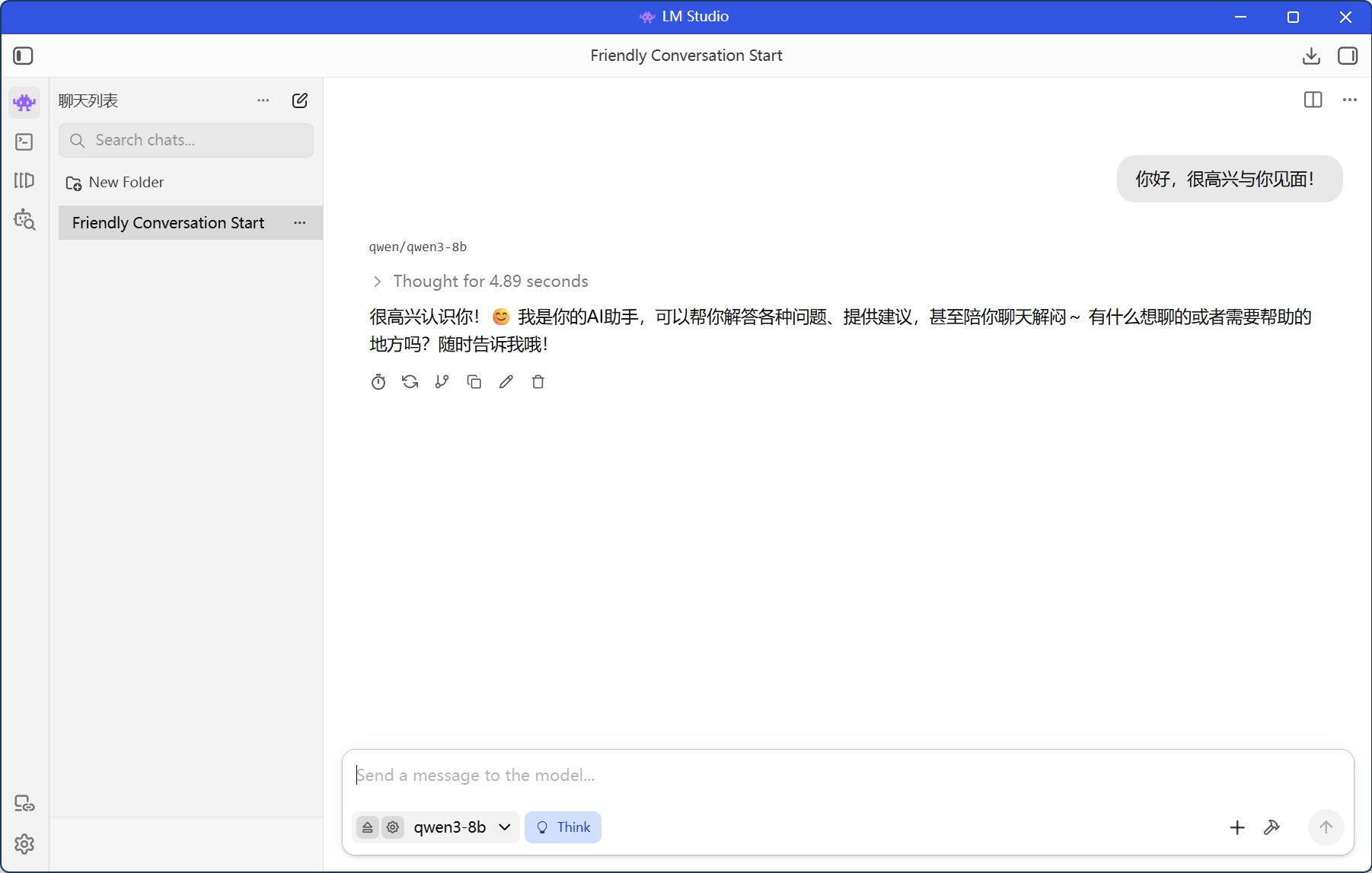
到此本地模型的部署就完成了。
总结
个人电脑的配置一般都不足以运行参数量太大的模型,低参数的小模型的智力确实有限,很难用于实际工作场景,如果你有需要可以用于一些本地的翻译,摘要,或者博客整理文章的简单任务,或者只是聊聊天。总之本地部署的应用场景比较有限,就当尝个鲜了。
有任何问题欢迎评论区留言,我会尽快回复。

